import re
import sys
import os
import networkx as nx
import pydot
def remove_comments_and_strings(code):
"""
Javaコードから、ブロックコメント、行コメント、文字列リテラルを除去して、
制御構造の誤検出を防ぎます。
"""
code = re.sub(r'/\*.*?\*/', '', code, flags=re.DOTALL) # ブロックコメント除去
code = re.sub(r'//.*', '', code) # 行コメント除去
code = re.sub(r'"(?:\\.|[^"\\])*"', '""', code) # 文字列リテラル除去
return code
def extract_methods(code):
"""
簡易的な正規表現と括弧カウントにより、
Javaコード内の各メソッドブロックを抽出します。
"""
method_pattern = re.compile(
r'(public|protected|private|static|\s)+[\w\<\>\[\]]+\s+\w+\s*\([^)]*\)\s*\{'
)
methods = []
for match in method_pattern.finditer(code):
start_index = match.end() - 1 # '{' の位置
brace_count = 1
end_index = start_index + 1
while end_index < len(code) and brace_count > 0:
if code[end_index] == '{':
brace_count += 1
elif code[end_index] == '}':
brace_count -= 1
end_index += 1
method_body = code[match.start():end_index]
methods.append(method_body)
return methods
def extract_relevant_lines(method_code):
"""
巨大なメソッド全体ではなく、
テストケース作成などに必要な箇所(メソッドシグネチャおよび
if/for/while/case/catch/三項演算子、論理演算子などの決定点を含む行)だけを抽出します。
"""
lines = method_code.splitlines()
relevant_lines = []
# 制御フローに関わるキーワード(最初の非空行=シグネチャは必ず含む)
decision_keywords = ['if(', 'if (', 'for(', 'for (', 'while(', 'while (',
'case ', 'catch(', 'catch (', '?', '&&', '||']
signature_included = False
for line in lines:
stripped = line.strip()
if not signature_included and stripped:
relevant_lines.append(stripped)
signature_included = True
continue
for kw in decision_keywords:
if kw in stripped:
relevant_lines.append(stripped)
break
return relevant_lines
def generate_cfg(method_code):
"""
抽出されたメソッド内の必要な行から単純な制御フローグラフ(CFG)を作成します。
ノードは "Entry" → [各抽出行] → "Exit" とし、基本的な線形エッジに加え、
決定点ノードから 2 つ先のノードへ追加エッジ(True 分岐)を張ります。
"""
lines = extract_relevant_lines(method_code)
nodes = ["Entry"] + lines + ["Exit"]
G = nx.DiGraph()
for node in nodes:
G.add_node(node)
# 基本の線形エッジを追加
for i in range(len(nodes) - 1):
G.add_edge(nodes[i], nodes[i+1])
# 決定点(if, for, while, etc.)から 2 つ先のノードへ追加エッジ(True 分岐)を追加
decision_keywords = ['if', 'for', 'while', 'case', 'catch', '?', '&&', '||']
for i, node in enumerate(nodes):
if any(kw in node for kw in decision_keywords):
if i + 2 < len(nodes):
G.add_edge(node, nodes[i+2])
return G
def generate_dot(G):
"""
networkx のグラフ G を DOT 言語の文字列に変換して返します。
"""
dot_str = "digraph CFG {\n"
for node in G.nodes():
# ノードラベルはダブルクォートで囲む(エスケープはここでは単純化)
dot_str += f' "{node}" [label="{node}"];\n'
for u, v in G.edges():
dot_str += f' "{u}" -> "{v}";\n'
dot_str += "}\n"
return dot_str
def validate_dot(dot_code):
"""
生成された DOT コードが正しくパースできるかを pydot を使って検証します。
正常なら (True, "OK")、エラーがあれば (False, エラーメッセージ) を返します。
"""
try:
graphs = pydot.graph_from_dot_data(dot_code)
if not graphs or len(graphs) == 0:
return False, "DOTコードからグラフが生成されませんでした。"
return True, "DOTコードは正しいです。"
except Exception as e:
return False, str(e)
def write_fix_report(report_filename, output_filename, error_message):
"""
エラー発生時に、修正箇所・修正内容を指摘したレポートファイルを出力します。
レポートは、対象の出力ファイル名とエラーメッセージ、考えられる原因および修正案を含みます。
"""
report_text = (
f"--- 修正レポート ---\n"
f"対象ファイル: {output_filename}\n\n"
f"【エラーメッセージ】\n{error_message}\n\n"
f"【考えられる原因と修正案】\n"
f"1. generate_dot 関数内で、ノードラベルやエッジの記述に誤りがある可能性があります。\n"
f" - 各ノードラベルはダブルクォートで囲む必要があります。\n"
f" - エッジの形式は \"source\" -> \"target\"; という形式にする必要があります。\n"
f"2. ノード名に特殊文字や未エスケープの文字が含まれていないか確認してください。\n"
f"3. DOT 言語の構文(セミコロンの付与、引用符の対応など)を再確認し、必要に応じて generate_dot 関数の実装を修正してください。\n\n"
f"【対象箇所】\n"
f"- generate_dot 関数\n\n"
f"上記の点を確認・修正してください。"
)
with open(report_filename, 'w', encoding='utf-8') as f:
f.write(report_text)
def main(java_filename):
"""
指定した Java ファイルから各メソッドを抽出し、
各メソッドの制御フローグラフ(CFG)を DOT 言語のテキストファイルとして出力し、
さらに生成された DOT コードが正しいか検証し、エラーがあれば修正内容を指摘したレポートファイルを出力します。
"""
with open(java_filename, 'r', encoding='utf-8') as f:
code = f.read()
code = remove_comments_and_strings(code)
methods = extract_methods(code)
if not methods:
print("Javaファイルからメソッドが見つかりませんでした。")
return
base_name = os.path.splitext(os.path.basename(java_filename))[0]
for idx, method in enumerate(methods, start=1):
G = generate_cfg(method)
dot_code = generate_dot(G)
output_filename = f"{base_name}_method_{idx}.dot"
with open(output_filename, 'w', encoding='utf-8') as f:
f.write(dot_code)
# DOTコードの検証
valid, message = validate_dot(dot_code)
if valid:
print(f"Method {idx}: DOT file generated and validated successfully: {output_filename}")
else:
print(f"Method {idx}: DOT file generated but validation failed: {output_filename}")
print("Error:", message)
# 修正レポートファイルを出力
report_filename = f"fix_report_{base_name}_method_{idx}.txt"
write_fix_report(report_filename, output_filename, message)
print(f"Fix report generated: {report_filename}")
if __name__ == '__main__':
if len(sys.argv) < 2:
print("Usage: python java_cfg_dot.py <JavaFile>")
sys.exit(1)
java_filename = sys.argv[1]
main(java_filename)
カテゴリー: 投資
カテゴリー
サイクロマティック複雑度
import re
import sys
def remove_comments_and_strings(code):
"""
コメント(ブロックコメント、行コメント)や文字列リテラルを除去し、
制御構造キーワードの誤検出を防ぎます。
"""
# ブロックコメントの除去 (DOTALLオプションで改行も含む)
code = re.sub(r'/\*.*?\*/', '', code, flags=re.DOTALL)
# 行コメントの除去
code = re.sub(r'//.*', '', code)
# 文字列リテラルの除去(単純に "" に置換)
code = re.sub(r'"(?:\\.|[^"\\])*"', '""', code)
return code
def extract_methods(code):
"""
シンプルな正規表現と括弧のカウントにより、
ソース内の各メソッドブロックを抽出します。
"""
method_pattern = re.compile(
r'(public|protected|private|static|\s)+[\w\<\>\[\]]+\s+\w+\s*\([^)]*\)\s*\{'
)
methods = []
for match in method_pattern.finditer(code):
start_index = match.end() - 1 # '{' の位置
brace_count = 1
end_index = start_index + 1
while end_index < len(code) and brace_count > 0:
if code[end_index] == '{':
brace_count += 1
elif code[end_index] == '}':
brace_count -= 1
end_index += 1
method_body = code[match.start():end_index]
methods.append(method_body)
return methods
def count_decision_points(method_code):
"""
以下のキーワードに着目して決定点をカウントします。
- if
- for
- while
- case
- catch
- 三項演算子 '?'
- 論理演算子 '&&' および '||'
"""
decisions = 0
decisions += len(re.findall(r'\bif\s*\(', method_code))
decisions += len(re.findall(r'\bfor\s*\(', method_code))
decisions += len(re.findall(r'\bwhile\s*\(', method_code))
decisions += len(re.findall(r'\bcase\b', method_code))
decisions += len(re.findall(r'\bcatch\s*\(', method_code))
decisions += len(re.findall(r'\?', method_code))
decisions += len(re.findall(r'&&', method_code))
decisions += len(re.findall(r'\|\|', method_code))
return decisions
def extract_relevant_lines(method_code):
"""
巨大なメソッド全体ではなく、
テストケース作成のために必要な箇所(メソッドシグネチャおよび決定点を含む行)だけを抽出して返します。
"""
lines = method_code.splitlines()
relevant_lines = []
decision_keywords = ['if(', 'if (', 'for(', 'for (', 'while(', 'while (',
'case ', 'catch(', 'catch (', '?', '&&', '||']
signature_included = False
for line in lines:
stripped = line.strip()
if not signature_included and stripped:
relevant_lines.append(stripped)
signature_included = True
continue
for kw in decision_keywords:
if kw in stripped:
relevant_lines.append(stripped)
break
return "\n".join(relevant_lines)
def calculate_cyclomatic_complexity(java_filename):
"""
指定したJavaファイルからサイクロマティック複雑度を算出し、
以下の項目を出力します。
・E: グラフのエッジ数
・N: グラフのノード数
・P: 連結成分数(ここではメソッド数)
・M: サイクロマティック複雑度
また、算出対象となったロジックの必要な箇所(決定点を含む部分)と、
各メソッドごとのE, N, P, 複雑度も出力します。
"""
with open(java_filename, 'r', encoding='utf-8') as f:
code = f.read()
code = remove_comments_and_strings(code)
methods = extract_methods(code)
if not methods:
methods = [code]
global_decisions = 0
print("【各メソッドごとの算出対象ロジックおよび統計】")
for idx, method in enumerate(methods, start=1):
d = count_decision_points(method)
global_decisions += d
# 各メソッドの統計計算
method_P = 1 # 各メソッドは1つの連結成分
method_M = d + 1 # 複雑度 = d + 1
method_N = d + 2 # ノード数 = d + 2
method_E = 2 * d + 1 # エッジ数 = 2*d + 1
relevant = extract_relevant_lines(method)
print(f"\n---- メソッド {idx} ----")
print("【対象ロジック】")
print(relevant)
print("【統計】")
print(" E (エッジ数):", method_E)
print(" N (ノード数):", method_N)
print(" P (連結成分数):", method_P)
print(" サイクロマティック複雑度:", method_M)
# グローバル統計(全メソッド合算)
P = len(methods)
global_M = global_decisions + P
global_N = global_decisions + 2 * P
global_E = 2 * global_decisions + P
print("\n【全体のサイクロマティック複雑度の結果】")
print("E (グラフのエッジ数):", global_E)
print("N (グラフのノード数):", global_N)
print("P (連結成分数/メソッド数):", P)
print("サイクロマティック複雑度:", global_M)
if __name__ == '__main__':
if len(sys.argv) < 2:
print("Usage: python cyclomatic.py <JavaFile>")
sys.exit(1)
java_filename = sys.argv[1]
calculate_cyclomatic_complexity(java_filename)
カテゴリー
Listの中のMapを検索
List<Map<String, String>> list = new ArrayList<>();
list.add(new HashMap<String, String>() {{ put("id", "1"); put("name", "aaa"); }});
list.add(new HashMap<String, String>() {{ put("id", "2"); put("name", "bbb"); }});
boolean exists = list.stream().anyMatch(map -> map.get("id").equals("aaa"));
if (exists) {
System.out.println("存在します");
} else {
System.out.println("存在しません");
}
List<Map<String, String>> list = new ArrayList<>();
list.add(new HashMap<String, String>() {{ put("id", "1"); put("name", "aaa"); }});
list.add(new HashMap<String, String>() {{ put("id", "2"); put("name", "bbb"); }});
// キーが存在する場合は、そのリストを取得
Optional<Map<String, String>> mapOptional = list.stream().filter(map -> map.get("id").equals("aaa")).findAny();
if (mapOptional.isPresent()) {
// キーが存在する場合は、そのリストにMapを追加
mapOptional.get().add(new HashMap<String, String>() {{ put("key", "value"); }});
} else {
System.out.println("存在しません");
}String filePath = "test.txt";
// FileReaderとBufferedReaderのMockを作成
FileReader mockFileReader = Mockito.mock(FileReader.class);
BufferedReader mockBufferedReader = Mockito.mock(BufferedReader.class);
// FileReaderのthenReturnメソッドを利用して、テストデータを設定
Mockito.when(mockFileReader.read()).thenReturn("テストデータ");
// BufferedReaderのコンストラクタをMock化
Mockito.when(new BufferedReader(mockFileReader)).thenReturn(mockBufferedReader);
// テスト対象のコードを実行
BufferedReader br = new BufferedReader(new FileReader(filePath));
String line = br.readLine();
// アサーション
assertEquals("テストデータ", line);
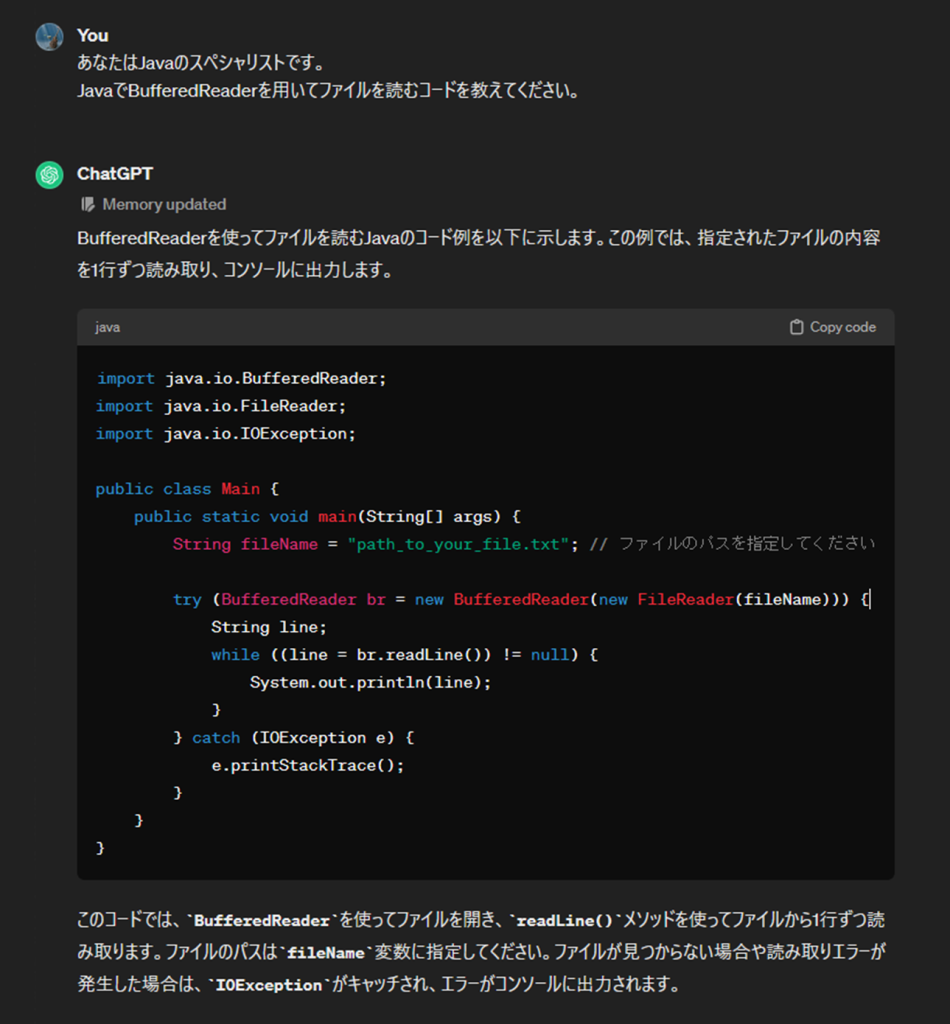
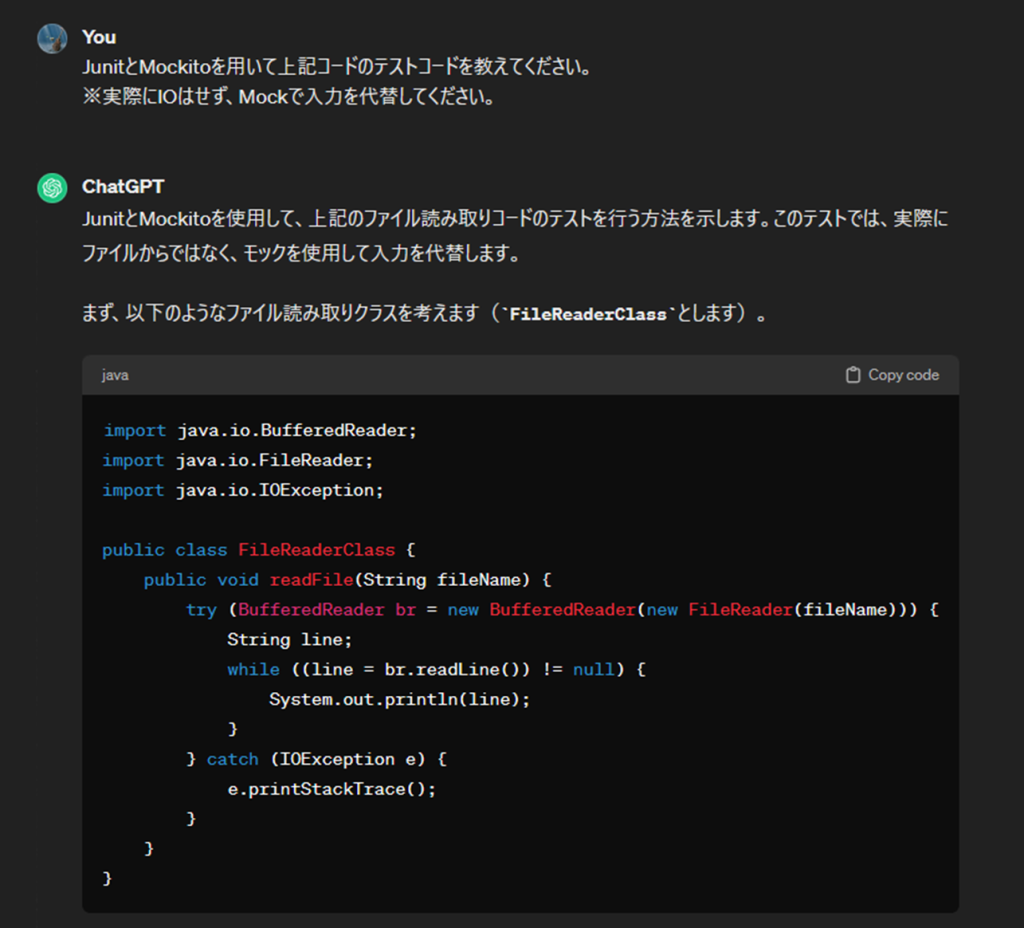
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class FileReaderClass {
public void readFile(String fileName) {
try (BufferedReader br = new BufferedReader(new FileReader(fileName))) {
String line;
while ((line = br.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
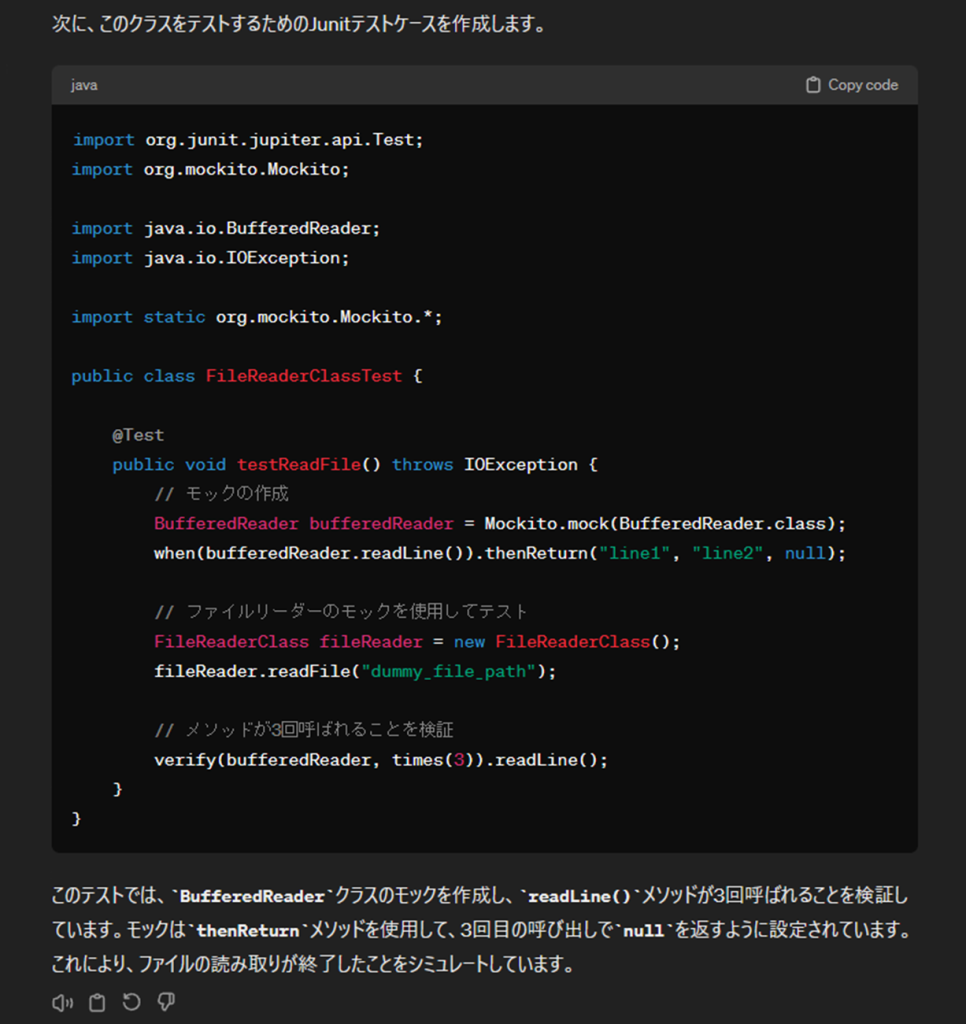
import org.junit.jupiter.api.Test;
import org.mockito.Mockito;
import java.io.BufferedReader;
import java.io.IOException;
import static org.mockito.Mockito.*;
public class FileReaderClassTest {
@Test
public void testReadFile() throws IOException {
// モックの作成
BufferedReader bufferedReader = Mockito.mock(BufferedReader.class);
when(bufferedReader.readLine()).thenReturn("line1", "line2", null);
// ファイルリーダーのモックを使用してテスト
FileReaderClass fileReader = new FileReaderClass();
fileReader.readFile("dummy_file_path");
// メソッドが3回呼ばれることを検証
verify(bufferedReader, times(3)).readLine();
}
}
Sub ValidateItemNumbers()
Dim ws As Worksheet
Set ws = ActiveSheet ' 現在アクティブなシートを使用
Dim lastRow As Long
lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row ' A列で最後の行を取得
Dim re As Object
Set re = CreateObject("VBScript.RegExp")
re.Pattern = "(\d+(-\d+)*)\."
re.Global = False
Dim currentNums() As Long
ReDim currentNums(1 To 10) ' 仮に階層は10までとする
Dim i As Long, j As Long
Dim isValid As Boolean
isValid = True ' バリデーションの結果を保持するフラグ
For i = 1 To lastRow
Dim cellValue As String
cellValue = Trim(ws.Cells(i, 1).Text)
If re.Test(cellValue) Then
Dim match As Object
Set match = re.Execute(cellValue)
' マッチしたパターンを即時ウィンドウに表示
Debug.Print match(0).Value
Dim parts() As String
parts = Split(match(0).SubMatches(0), "-")
Dim levels As Integer
levels = UBound(parts) + 1
' 階層毎に数値を検証
For j = 1 To levels
Dim partNum As Long
partNum = Val(parts(j - 1))
' 数値が期待されるシーケンスと一致しない場合
If currentNums(j) + 1 <> partNum Then
ws.Cells(i, 1).Interior.Color = RGB(255, 0, 0) ' セルの色を赤に変更
isValid = False
Exit For
Else
currentNums(j) = partNum ' 現在の数値を更新
End If
Next j
' 現在のレベルより深いレベルの数値をリセット
For j = levels + 1 To UBound(currentNums)
currentNums(j) = 0
Next j
End If
Next i
If isValid Then
MsgBox "全ての項番が正しく採番されています。", vbInformation
Else
MsgBox "いくつかの項番が正しく採番されていません。赤く塗られたセルを確認してください。", vbExclamation
End If
End Sub
Sub ValidateItemNumbers()
Dim ws As Worksheet
Set ws = ActiveSheet ' 現在アクティブなシートを使用
Dim lastRow As Long, lastCol As Long
lastRow = ws.Cells(ws.Rows.Count, "A").End(xlUp).Row ' A列で最後の行を取得
lastCol = ws.Cells(1, ws.Columns.Count).End(xlToLeft).Column ' 1行目で最後の列を取得
Dim re As Object
Set re = CreateObject("VBScript.RegExp")
re.Pattern = "(\d+(-\d+)*)\.|."
re.Global = False
Dim currentNums() As Long
ReDim currentNums(1 To 10) ' 仮に階層は10までとする
Dim i As Long, j As Long, col As Long
Dim isValid As Boolean
isValid = True ' バリデーションの結果を保持するフラグ
For i = 1 To lastRow
For col = 1 To lastCol ' 各列をループ
Dim cellValue As String
cellValue = Trim(ws.Cells(i, col).Text)
If cellValue <> "" And re.Test(cellValue) Then ' セルが空白でなく、正規表現に一致する場合
Dim match As Object
Set match = re.Execute(cellValue)
' マッチしたパターンを即時ウィンドウに表示
Debug.Print match(0).Value
Dim parts() As String
parts = Split(match(0).SubMatches(0), "-")
Dim levels As Integer
levels = UBound(parts) + 1
' 階層毎に数値を検証
For j = 1 To levels
Dim partNum As Long
partNum = Val(parts(j - 1))
' 数値が期待されるシーケンスと一致しない場合
If currentNums(j) + 1 <> partNum Then
ws.Cells(i, col).Interior.Color = RGB(255, 0, 0) ' セルの色を赤に変更
isValid = False
Exit For
Else
currentNums(j) = partNum ' 現在の数値を更新
End If
Next j
' 現在のレベルより深いレベルの数値をリセット
For j = levels + 1 To UBound(currentNums)
currentNums(j) = 0
Next j
Exit For ' 同じ行に項番が複数存在しないため、次の行に移動
End If
Next col
Next i
If isValid Then
MsgBox "全ての項番が正しく採番されています。", vbInformation
Else
MsgBox "いくつかの項番が正しく採番されていません。赤く塗られたセルを確認してください。", vbExclamation
End If
End Sub
カテゴリー
【ルール】 情報を階層的に整理するためのもので、各項目が特定のレベルまたは「階層」を示しています。以下のように説明することができます: 1. **大項番**:これは最上位のカテゴリまたはセクションを示します。例えば、「1.」や「2.」などです。インクリメントして設定されます。 2. **中項番**:これは大項番の下にあるサブカテゴリまたはサブセクションを示します。例えば、「1-1.」や「1-2.」などです。インクリメントして設定されます。 3. **小項番**:これは中項番の下にあるさらに詳細なカテゴリまたはサブセクションを示します。例えば、「1-1-1.」や「1-1-2.」などです。インクリメントして設定されます。 4. **枝番**:これは小項番の下にある詳細なカテゴリまたはサブセクションを示します。例えば、「1-1-4-1.」や「1-1-4-2.」などです。インクリメントして設定されます。 枝番の下にさらに枝番がつくことがあります。 採番の後の文字列は、その項目が何を表しているかを示す小見出しです。これは任意で、文書の内容によって異なります。 上記ルールのフォーマットを正規表現であらわすと(\d+(-\d+)*)\.になります。 この採番体系は、情報を整理し、読者が特定の情報を簡単に見つけられるようにするためのものです。それぞれの数字は、その項目が文書全体のどの部分に位置しているかを示しています。 大項番から枝番まで、数字が増えるごとに詳細レベルが深くなります。この体系を使用すると、文書の構造を一目で理解することができます。
1. 大項番 説明 1-1. 中項番 1-1-1. 小項番 説明 1-1-2. 小項番 説明 1-1-3. 枝番1 説明 1-1-4. aaa 説明 1-1-4-1. 枝番2 1-1-4-2. 枝番2 1-2. bbb 説明 1-2-1. cccc 説明 2. dddd 説明 2-1. eeeeee 説明
カテゴリー
トイレの換気扇の位置
ひどいと思いませんか?

@RequestMapping(value = "/webhook",method = RequestMethod.POST, produces = "application/json")
public void webhook(HttpServletRequest request,HttpServletResponse response) throws StripeException, IOException {
System.out.println("------------------------------------");
System.out.println("catch!webhook");
String result = request.getReader().lines().collect(Collectors.joining("\r\n"));
System.out.println(result);
}
カテゴリー
stripeアクセス
@PostMapping("/hello2")
private String stripeAccess() throws StripeException {
// This is your test secret API key.
Stripe.apiKey = "sk_test_51LG9wvEbZcPb8qcKSD7pJKgdgeg9sSXJutIPL2VlbQWYp8T3EUTKEj1WIFRfQEINGOwWTOFQUoseMiHmzSeH2BQ300BSZeAfj9";
staticFiles.externalLocation(
Paths.get("public").toAbsolutePath().toString());
String YOUR_DOMAIN = "http://localhost:8080";
//商品(product)設定
Map<String, Object> product_data1 = new HashMap<>();
product_data1.put("name","商品A");
product_data1.put("description","A商品の説明");
product_data1.put("tax_code","txcd_99999999");
//商品(product)メタデータ設定
Map<String, Object> meta = new HashMap<>();
meta.put("商品コード","111100011");
meta.put("商品カタログ","xxxxx");
product_data1.put("metadata",meta);
Map<String, Object> product_data2 = new HashMap<>();
product_data2.put("name","商品B");
product_data2.put("description","B商品の説明");
product_data2.put("tax_code","txcd_99999999");
//値段(price)設定
Map<String, Object> price_data1 = new HashMap<>();
price_data1.put("product_data",product_data1);
price_data1.put("currency","JPY");
price_data1.put("unit_amount_decimal",400);// price_data1.put(“tax_behavior”,”inclusive”);
Map<String, Object> price_data2 = new HashMap<>();
price_data2.put("product_data",product_data2);
price_data2.put("currency","JPY");
price_data2.put("unit_amount_decimal",700);
price_data2.put("tax_behavior","inclusive");
//明細(line)設定
Map<String, Object> lineItem1 = new HashMap<>();
lineItem1.put("quantity", 2);
lineItem1.put("price_data",price_data1);
Map<String, Object> lineItem2 = new HashMap<>();
lineItem2.put("quantity", 3);
lineItem2.put("price_data",price_data2);
//Item設定
List<Object> lineItems = new ArrayList<>();
lineItems.add(lineItem1);
lineItems.add(lineItem2);
//可能な支払い方法
List<Object> paymentmethod = new ArrayList<>();
paymentmethod.add("card");
paymentmethod.add("alipay");
//checkOutSessionパラメタ
Map<String, Object> params = new HashMap<>();
params.put(
"success_url",
YOUR_DOMAIN + "/success"
);
params.put(
"cancel_url",
YOUR_DOMAIN + "/cancel"
);
params.put("customer","cus_MI5Yu1Mriu7zXN");
params.put("line_items", lineItems);
params.put("client_reference_id","cus_MI4kKPMyy4jnVh");
params.put("mode", "payment");
params.put("payment_method_types",paymentmethod);
Session session = Session.create(params);
System.out.println(session);
System.out.println("endendend");
return "redirect:" + session.getUrl();
}toexcel使い方
toexcelバッチのカレントフォルダに有るpngファイルを
①resizeして、縦横1/2のサイズに変更。元のファイルはtmpディレクトリにバックアップ。
②excelに貼り付け
するpythonです。
使用方法
1.pngファイルがあるディレクトリに下記4ファイルを置く。
2.toexcel.batをダブルクリック
3.result.xlsが作成される。
又、scripts.logというログファイルが出力されます。
※excelに貼り付ける順番はファイル名順です。
ファイル
・imgpaste.py ← excelに貼り付けるスクリプト
・logger.yaml ← 設定ファイル
・resize.py ← 画像ファイルを1/2にするスクリプト
・toexcel.bat ← エクセルに貼り付けるバッチファイル(↓)
python resize.py
python imgpaste.py
pause